上海信弘智能科技有限公司,信弘,智能,信弘智能科技,Elite Partner,Omniverse,智能科技,NVIDIA GPU,NVIDIA DGX, vGPU,TESLA,QUADRO,AI,AI培训,AI课程,人工智能,解决方案,DLI,Mellanox,IB, 深度学习,RTX,IT,ORACLE 数据库,ORACLE云服务,深度学习学院,bigdata,大数据,数据安全备份,鼎甲,高性能计算, 虚拟机,虚拟桌面,虚拟软件,硬件,软件,加速计算,HPC,超算,服务器,虚拟服务器,IT咨询,IT系统规划,应用实施,系统集成
评估用于企业级 RAG 的检索器
关于设计和评估检索增强生成(RAG)系统的讨论由来已久,涉及多个方面。即使我们只看检索本身,开发人员也会选择性地采用多种技术,如查询分解、重写、构建软过滤器等,以提高 RAG 管道的准确性。虽然技术因系统而异,但嵌入模型通常是 RAG 中每个检索管道的核心。
嵌入,特别是密集嵌入,用于表达文本的语义结构。由于 RAG 中的所有检索器都必须解决对原始文本语义理解的关键问题,因此最重要的是要有一个系统的评估流程来选择正确的检索器。
一般的检索基准,如海量文本嵌入基准(MTEB)和红外基准(BEIR),经常被用作评估检索器的代用工具。生产中遇到的数据类型对确定学术基准的相关性起着至关重要的作用。此外,在评估企业级 RAG 时,度量标准的选择也应视使用情况而定。
在本篇文章中,您将了解到:
一些最流行的学术基准包含哪些内容,以及如何最好地利用它们作为代理。
评估检索器的推荐指标。
数据混合对基准的影响
评估检索的最佳数据是您自己的数据。理想情况下,您需要构建一个干净且贴有标签的评估数据集,以最好地反映您在生产中看到的情况。最好建立一个自定义基准,用于评估不同检索器的质量,而不同检索器的质量会因领域和任务的不同而有很大差异。
在没有标记良好的评估数据的情况下,很多人会求助于两种流行的基准:MTEB 和 BEIR 作为替代。然而,一个关键问题是
"这些基准测试中的数据集是否真正代表了您的工作负载?"
回答这个问题至关重要,因为评估不相关案例的性能可能会导致您对 RAG 管道产生错误的信心。
流行通用的基准是什么?
RAG 系统通常作为聊天机器人的一部分部署。检索器的任务是根据用户的查询找到相关段落,为 LLM 提供上下文。BEIR 基准自2021 年推出以来,已成为评估信息检索嵌入的首选标准。
由 Hugging Face 托管的MTEB 结合了 BEIR 和其他各种数据集,用于评估不同任务中的嵌入模型,如分类、聚类、检索、排序等。
检索基准
BEIR 有 17 个基准数据集,涵盖不同的文本检索任务和领域,而 MTEB 则由 58 个数据集组成,涵盖 8 种不同嵌入任务的 112 种语言。每个数据集都用于衡量嵌入模型的各种应用性能--检索、聚类和摘要。考虑到对 RAG 的关注,您必须考虑哪些性能指标和数据集最有助于评估与您的使用案例相一致的问题解答 (QA) 检索解决方案。
有几个数据集可以解决根据输入查询查找相关段落的任务:
HotpotQA 和NaturalQuestions (NQ) 对一般 QA 进行了评估。
FiQA 专注于与金融数据相关的质量保证。
NFCorpus 包含医疗领域的 QA对。
HotpotQA:一般问题-段落对
输入:Scott Derrickson 和 Ed Wood 是同一国籍吗?
目标:斯科特-德里克森 斯科特-德瑞克森(生于 1966 年 7 月 16 日),美国导演、编剧和制片人。现居加利福尼亚州洛杉矶。他最著名的作品是执导恐怖片《中邪》、《艾米莉-罗丝的驱魔仪式》和《除魔卫士》,以及 2016 年漫威电影宇宙作品《奇异博士》。
NQ:一般问题-段落对
输入:什么是资产负债表上的非控股权益?
目标:在会计中,少数股东权益(或非控股权益)是指子公司的股票中母公司不拥有的部分。子公司少数股东权益的规模一般低于已发行股票的 50%,否则该公司一般不再是母公司的子公司。
不过,BEIR 中的 Quora 和 Arguana 等其他数据集关注的是质量保证以外的任务。
Quora :查找重复问题
输入:我应该在 Quora 上问哪个问题?
目标:在 Quora 上提什么问题好?
论据:查找反事实段落
输入:杀害动物是不道德的 作为进化了的人类,我们的道德责任是为了生存而尽可能少地给动物造成痛苦。因此,如果我们不需要为了生存而给动物造成痛苦,我们就不应该这样做。鸡、猪、羊和牛等农场动物和我们一样都是有生命的生物--它们是我们进化过程中的表亲,和我们一样能够感受到快乐和痛苦。18 世纪的功利主义哲学家杰里米-边沁(Jeremy Bentham)甚至认为,动物的痛苦与人类的痛苦同样严重,并将人类优越的观念比作种族主义。在我们不需要的情况下,养殖和捕杀这些动物作为食物是错误的。[...]
目标:人类与动物之间存在着巨大的道德差异。与动物不同,人类能够进行理性思考,并能改变周围的世界。地球上的其他生物是供人类使用的,包括吃肉。基于所有这些原因,我们说男人和女人有权利,而动物没有。
这些例子强调了仔细审核基准数据和选择与用例密切相关的问题的重要性。在使用 BEIR 基准指导决策时,请考虑以下几点:
构成 BEIR 的所有数据集是否都与您的 RAG 应用相关?
不同基准的样本分布是否准确地代表了用户通常提出的问题?
我们的一般建议是在相关子集上评估检索器,如 HotpotQA、NQ 和 FiQA,因为它们是通用质量保证应用的代表。但是,如果您的 RAG 管道有独特的考虑因素,我们建议在您的评估混合中加入前述来源的代表性数据。
如何为保证质量基准而选择最佳模型
让我们深入探讨如何选择或策划最符合您的评估的基准。
领域和质量
在检查不同的 BEIR 数据集时,您可能会注意到有些数据集是特定领域的。如果您想为技术手册说明建立一个 RAG 系统,您可能需要考虑来自同一领域的数据集,这些数据集具有最能代表您的使用案例的类似问题。TechQA 就是这样一个数据集,它是一个领域适应数据集,包含用户在技术论坛上提出的实际问题。TechQA 并不在 BEIR 基准数据集之列,但它可能是与您的 IT /技术支持用例具有相似领域的候选数据集。例如:
问题标题:"Citrix 上的 Datacap"
问题文本:"大家好,我们能否在 Citrix 上操作 Datacap 瘦客户机?"
回答: "通过广域网访问 Datacap 的远程用户可以使用基于 Web 的 Taskmaster("瘦客户机")或在脱机模式下运行的 FastDoc Capture"。"
上下文:"在广域网(WAN) 上部署 Datacap 服务器和客户端的最佳实践是什么?答 通过广域网访问 Datacap 的远程用户可使用基于 Web 的 Taskmaster "瘦客户端",或在脱机模式下运行的 FastDoc Capture。Datacap 粗客户端(DotScan、DotEdit)和实用程序(NENU、指纹维护工具)需要局域网通信速度和低延迟,以获得响应性能。将所有Datacap Taskmaster 服务器、Rulerunner 服务器、Web 服务器、文件服务器和数据库连接到单一高性能局域网,以获得最佳效果。任务主服务器、共享文件和数据库之间的网络延迟会导致任务监控器和数据密集型操作的性能下降。一些客户使用 Citrix 或其他远程访问技术在远程站点成功运行 Datacap 厚客户端。IBM 没有测试或寻求 Citrix 认证,也不为 Citrix 提供支持。如果您在 Citrix 上部署 Datacap 客户端并遇到问题,作为调查的一部分,IBM 可能会要求您在 Citrix 外部重现问题。有关部署建议和图表,请参阅题为 "使用 IBM Production Imaging Edition 和 IBM Datacap Capture 实施图像解决方案 "的 IBM 红皮书第 2.5 节。"
训练数据:域内与域外比较
BEIR 的几个基准数据集将训练数据和测试数据分开。虽然将训练分割数据纳入检索器的训练数据集是没有问题的,但它会使 MTEB 基准上的模型性能比较及其在未见的、企业特定数据上的有效性变得复杂。如果包含训练分化,模型就会从与测试数据集相同的分布中学习,从而导致测试数据集上的性能指标膨胀。这种差异通常称为域内与域外的比较。
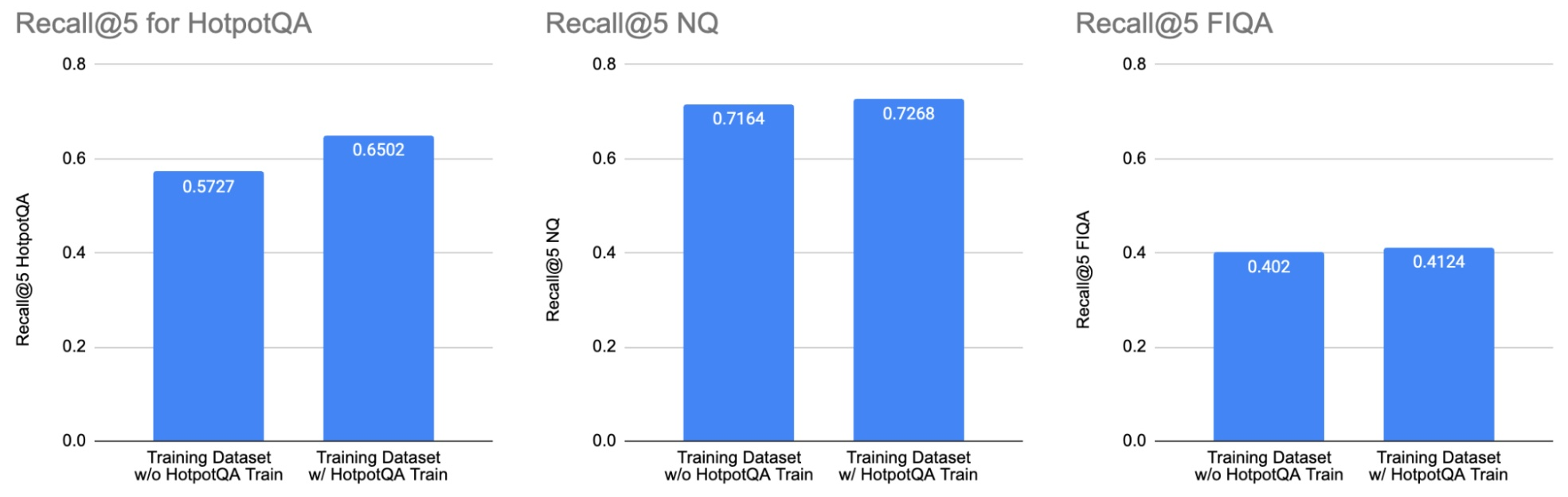
图 1. 比较基准图,展示了在微调 e5 大型无监督模型时加入 HotPotQA 训练拆分的影响。HotPotQA训练拆分仅在 HotPotQA 基准上提高了性能
我们对 e5_large_unsupervised 模型进行了两次微调:一次是使用不包含 HotpotQA 训练拆分的训练数据集(左侧条形图),另一次是使用包含HotpotQA 训练拆分的训练数据集(右侧条形图)。包含 HotpotQA 训练拆分的数据集提高了 HotpotQA 测试数据集的性能(左柱状图)。但是,它并没有明显改变 NQ(中间柱状图)和 FIQA(右侧柱状图)的性能。这说明了在解释公共基准结果时,检查用于训练模型的数据集的重要性。
许多模型都是在 MSMarco、NQ 和 NLI(包括 BEIR 数据集的训练分集)的混合数据集上训练的。例如,"使用大型语言模型改进文本嵌入 "研究在附录中提供了训练数据集的详细信息。在论文中,表 1 说明了合成+MS-Marco 和合成+Full 配置之间的性能差异。一般来说,人工生成或注释数据比纯合成数据集能提供更好的质量评估。这种相关性也适用于数据集的大小。
总之,一般建议寻找与您的使用情况相符且样本量大的人工合成和注释数据集。
许可证
请注意,以下内容只是一种解释,并非法律建议--建议您在考虑任何问题时咨询您的法律团队。
另一个需要考虑的重要方面是与预训练模型相关的许可和使用条款。虽然HuggingFace 平台上的许多预训练模型都是根据 MIT 或 Apache 2.0 许可共享的,但审查用于预训练的数据集是非常重要的,因为有些数据集可能有禁止商业应用的许可。请考虑使用预训练模型,该模型使用的训练数据已获得商业使用许可。
了解了数据的重要性,我们就掌握了评估的一个方面。另一个关键方面是我们用来衡量质量的指标。
评估指标
用于检索评估的指标主要有两种:
等级感知指标:这些指标考虑了检索文档的顺序或等级。在推荐系统或搜索引擎等场景中,让最相关的结果排在较靠前的位置是非常有益的。这方面的例子包括归一化折损累计增益(NDCG)。
排名无关指标:这些指标不考虑结果呈现的顺序。当目标是检测列表中是否存在相关条目,而不是它们的排名时,这些指标就非常有用。
现在,让我们深入探讨 Recall 和 NDCG 这两个在学术基准和排行榜中常见的指标。
召回率
召回率是一个与排名无关的指标,用于衡量检索到的相关结果的百分比:
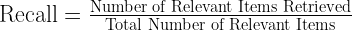
简单地说,如果给定查询有三个相关块,而检索到的前 5 个块中只有两个出现,那么召回率就是 ⅔ = 0.66。
你会在基准测试中看到一种流行的变体,即 recall@K ,它只考虑系统返回的前 K 个项目。但是,如果你的系统总是返回固定的 K 个条目,那么 recall@K 和召回率实际上是同一个指标。
在大多数信息检索场景中,当检索候选项的顺序并不重要时,召回率是一个非常好的指标。从RAG 的角度来看,如果您的信息块较小(300-500 个token),而且您检索的信息块较少,那么大多数 LLM 在检索 1500-2500 个 token 上下文时都不会遇到迷失在中间的问题。
如果给 LLM 的上下文相当长,那么它提取相关信息的能力就会因信息的位置而异。通常情况下,LLM 在信息位于顶部和底部时效果最佳,如果信息位于 "中间",则效果会明显降低。在较短的情况下,信息块的顺序并不重要,只要它们都包含在内即可。
归一化折损累计增益
归一化折损累计增益(NDCG)是一种等级感知指标,用于衡量检索信息的相关性和顺序。
累积增益跟踪的是相关性,检索列表中的每个条目都会根据其在回答查询时的有用性分配相关性分数。
根据位置进行折扣,位置越低,折扣越高,以激励更好的排名。
当使用不同数量的相关块时,归一化可统一不同查询的指标。
RAG 管道中检索的主要目标是使 LLM 能够执行提取式问答。当检索到的数据块过长(超过 4k tokens)或检索到大量数据块时,NDCG 就会变得非常重要,从而导致在长上下文中可能出现中间丢失的情况。此外,如果您的应用程序将数据块作为引用公开,您可能会发现检索到的数据块的顺序和相关性非常重要。
在许多实际应用中,最多 4K 标记的上下文就足够了,而召回率是推荐的指标,因为如果最相关的语块没有排在最前面,NDCG 就会受到惩罚。只要在合理大小的上下文中可以共享的 K 个检索结果中,LLM 就能有效利用这些信息来制定响应。
虽然召回率和 NDCG 是截然不同的方法,但它们往往表现出很高的相关性。在你的数据上召回率得分较高的检索模型很可能也会有较高的 NDCG 分数。
现在,让我们来探讨一个与基于文本的质量保证相关的检索基准,并与迄今为止的建议保持一致。
检索基准
NVIDIA NeMo Retriever 是 NVIDIA NeMo 框架的一部分,它提供的信息检索服务旨在简化将企业级 RAG 安全、轻松地集成到定制的生产型 AI 应用程序中的过程。其核心是英伟达检索 QA 嵌入模型,该模型在商业上可行的内部数据集上进行训练。
在图2中,我们展示了 MTEB/BEIR 相关子集(包括 NaturalQuestions、HotpotQA 和 FiQA )上的r ecall@5 分数。这些子集是 QA 任务的代表性 RAG 工作负载。
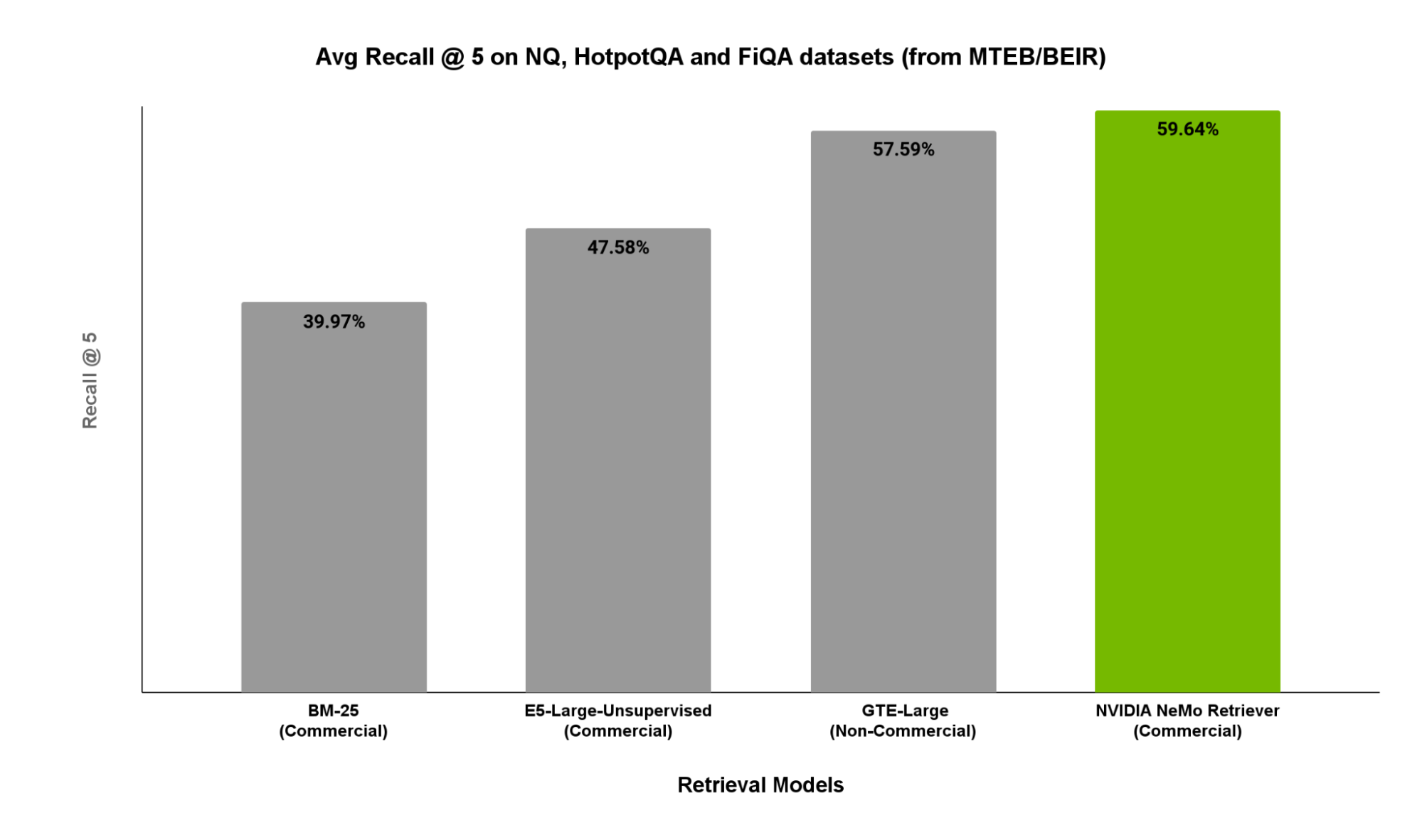
图 2. 在与一般基于文本的质量保证检索相关的 MTEB/BEIR 子集上比较流行检索模型/服务的 recall@5 分数。
如图 2 所示,NVIDIA Retrieval QA Embedding 的表现优于其他开源选项。
结论
在缺乏评估数据的情况下,必须准确定位学术基准套件中哪些部分能够接近您的使用案例,而不是对可能不相关的子集进行平均。此外,仅依赖学术基准也要谨慎,因为其中部分基准可能已被用于训练所考虑的检索器,从而可能导致对其在您的数据上的性能产生错误的信心。
此外,recall@K 和 NDCG 是两个最相关的指标,您可以选择两者的组合。如果只选择其中一个,召回率的解释更为简单,适用范围也更广。