上海信弘智能科技有限公司,信弘,智能,信弘智能科技,Elite Partner,Omniverse,智能科技,NVIDIA GPU,NVIDIA DGX, vGPU,TESLA,QUADRO,AI,AI培训,AI课程,人工智能,解决方案,DLI,Mellanox,IB, 深度学习,RTX,IT,ORACLE 数据库,ORACLE云服务,深度学习学院,bigdata,大数据,数据安全备份,鼎甲,高性能计算, 虚拟机,虚拟桌面,虚拟软件,硬件,软件,加速计算,HPC,超算,服务器,虚拟服务器,IT咨询,IT系统规划,应用实施,系统集成
支持 GPU 的容器云平台 - Kube Manager
助力数字中心的计算资源管理
在 GPU 用户较多的情况下,缺乏对 GPU 资源的统一分配与管理,导致 GPU 资源分配不均,出现闲置和抢占情况,利用率不高。此外,由于开发人员的习惯和所需要的环境不同,单台机器多个用户的开发环境存在相互影响的情况。
Kube Manager 作为一款容器云平台,能对大规模的 CPU 和 GPU 计算资源进行统一的管理和分配调度,提出相对应的解决方案。它可实现 GPU 资源动态分配,按需申请,避免资源分配不均的问题。并且支持 GPU 共享,单张 GPU 卡可供多人同时使用,减少了资源的相互抢占。此外,Kube Manager 通过容器技术可实现多人同时共用同一台机器,开发环境相互隔离互不影响。
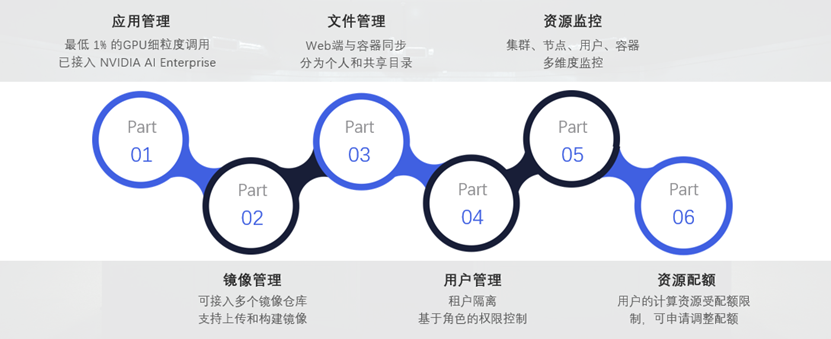
Kube Manager 主要包括资源监控、应用管理、镜像管理、文件管理、用户管理、资源配额这六个模块。
Kube Manager 的优势
1. 便捷的资源配置
- 创建应用时可快速选择所需的 CPU、内存、GPU 及显存资源
- 资源具有配额,禁止超额使用,配额可调整
- CPU 分配粒度为 1‰ 核,内存为 1 MB
2. 高效的应用创建
- 大幅简化操作,仅需选择镜像和资源配置即可创建应用
- 同时提供环境变量、启动命令等高级设置
- 系统会自动挂载 NFS,以长期存储和快速访问文件
3. 灵活的 GPU 调度
- 可选整卡、MIG 切分卡、按百分比选择 GPU
- 按百分比选择 GPU 时,最低可至 1% 利用率、0.25G 显存
4. 多维度监控
- 集群、节点、用户、容器多维度监控
- 展示 CPU、内存、网络、GPU 等资源使用情况
- 可根据需要进行深度定制
5. 持久文件存储
- 文件持久存储于 NFS 中,可持续使用,不会随容器停止而丢失
- 网页文件与容器同步,目录会自动挂载到容器内,方便操作
6. NVAIE 快速入口
- NVAIE,即 NVIDIA AI Enterprise,是一款端到端、云原生的 AI 预训练模型和数据分析软件套件
- NVIDIA AI Enterprise 经过 NVIDIA 认证,并包含全球企业支持,可保证 AI 项目快速实施和部署,商业使用需要额外购买 License
客户案例
上海交通大学数学院
Kube Manager 提供多种 GPU 调度方案,可以指定使用整卡、MIG 切分、按百分比切分。在服务器众多时,能够同时容纳多种方案以满足不同的 GPU 需求。上海交通大学数学院借助 Kube Manager 解决 GPU 资源分配和环境冲突问题,并且将多种服务器统一管理,提高了资源利用效率。
南京农业大学人工智能学院
借助 Kube Manager 容器云平台,南京农业大学人工智能学院多名师生不同业务的资源需求得到满足。显卡分别被十余个实例几乎占满,计算资源利用率大幅提高。与此同时,每天可完成的训练任务数量增加,模型开发周期也大为缩短。
浙江大学上海高等研究院
Kube Manager 集群灵活配置用户的资源配额和限制,防止资源过多占用和浪费。使用 Kube Manager 后,浙江大学上海高等研究院同时运行多个实例,资源不足时排队等待,利用夜间、假期训练任务,充分提高资源的利用率,任务训练效率也有了很大的提升。